Sprint Planning with GitHub issues
Curious about how to do Sprint Planning on GitHub? Below, we describe what sprints and sprint planning are, and how to do Sprint Planning on GitHub.
- What is a sprint?
- What is sprint planning?
- How to do sprint planning on GitHub
What is a sprint?
A sprint is a fixed-length iteration of work e.g. two or four weeks. Sprints are used by agile teams that embrace the Scrum methodology. During each sprint, the development team focuses on completing the issues they committed to finishing in that sprint. Before each sprint, the team commits to the set of issues they’ll complete during a sprint planning session.
What is Sprint Planning?
Sprint Planning is one of the four “ceremonies” of Scrum. The others are a Demo (showing the work completed in the previous sprint), a Daily Scrum (for the development team to sync up), and a Retrospective (for the team to review what went well and what didn’t go well in the last sprint).
During sprint planning, the development team and the product owner figure out what issues will be completed in the upcoming sprint.
Most agile teams will use a process similar to this:
- Each team should know their velocity. Velocity is a measure of amount of work the team can complete in a sprint based on the work they’ve completed in past sprints.
- Each issue should have an estimate (in time or points).
- The sum of those issues’ estimates is the amount of work that can be completed in the upcoming sprint.
For example, if your team’s velocity is 20 days of engineering work, and you have four issues each with an estimate of 5 days each, you can put those four issues into the upcoming sprint, but nothing more.
Planning your Sprints with GitHub
GitHub issues wasn’t built specifically for agile teams, but it’s possible for agile teams to use GitHub to plan sprints. We’ll cover the challenges with using GitHub to plan sprints, and then show you workarounds.
The challenges with using GitHub to plan Sprints
There are five main issues with using GitHub to plan Sprints.
- Issues live in multiple repositories
- No built-in notion of points
- No built-in notion of a backlog
- No Kanban board
- No way to see if your sprint fits your velocity
1. Issues live in multiple repositories
If your issues live in multiple repositories (for example, you might have an API repo, an iOS repo, and a frontend repo), getting a view of all your issues across repos in a single place in GitHub is impossible. A tool like Codetree can help with that, but otherwise doing sprint planning in GitHub is challenging.
2. No built-in notion of issue size
Scrum teams use points to estimate their issues. This is a key tenet of Scrum. “Points” aren’t a first-class citizen in GitHub, though you can use labels to estimate your issues as a workaround (see below).
3. No built-in notion of a backlog
GitHub doesn’t have a built-in notion of a Backlog like purpose-built agile tools do. It’s not a huge deal, but something you need to think about when designing your process to live on GitHub.
4. No Kanban board
GitHub has Projects, which are a Kanban-style tool. But Projects are time- and labour-intensive to use. The main reason is because Projects aren’t driven by a query. For example, you can’t see these issues on a Project board: “Show me all issues in the January milestone assigned to Sally or Dave”. In order to see those issues in a Project, you need to add them manually, one by one.
With Codetree, you can see your issues on a Kanban board filtered on dimensions like label, milestone, assignee, and a lot more. There’s no need to add them manually to a Kanban board - you just select the issues you want to see and see them on a Kanban board.
5. No way to see if your sprint fits your velocity
Since GitHub doesn’t have issue size as a first-class citizen, there’s no way to understand the amount of work you completed over the last few sprints. If you knew those, and averaged them, you’d understand what your team’s velocity was. This would help you plan the set of issues you could complete during sprint planning. We’ll show you a workaround to this, below.
Workarounds to use GitHub to plan Sprints
Now that we’ve covered the challenges with doing Sprint planning with GitHub, we’ll cover workarounds. There are four things to do to plan sprints with GitHub:
- Track your velocity
- Set up your Backlog
- Estimate your issues
- Move estimated issues to your Sprint
GitHub doesn’t have the notion of a “sprint”, but it does have a similar metaphor: a Milestone.
Each Milestone has only three elements: a Title, a Body, and an optional due date.
To start your sprint planning with GitHub, you’d create a Milestone. At Codetree our iterations last for one month, so we name them e.g. “June 2017” and set their due date to the end of the month.
Once you have a milestone, you’re ready to put issues into it. But first, you need to know what your team’s velocity is.
1. Tracking Velocity in GitHub
A reminder: velocity is a measure of the amount of work your team can complete in a sprint based on the work they’ve completed in past sprints.
To track your velocity in GitHub, you have to do two things:
- Label each issue with its estimate
- When a Sprint is done, sum the sizes of your closed issues
- Put your velocity in a spreadsheet to calculate your rolling average
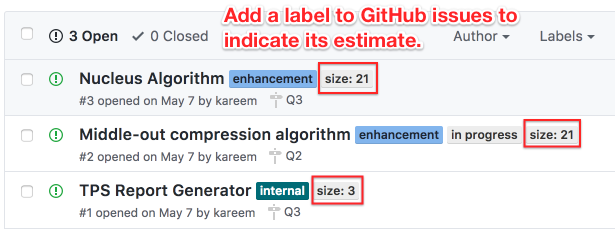
1. Label each issue with its estimate
The best way to understand your velocity in GitHub is to add a tag to each issue with its estimate. You’d apply the label “size: 3” to an issue if its estimate was 3, or “size: 10” to an issue with a size of 10.
In Codetree (a project management tool that syncs with your GitHub issues) an issue’s Size is a first-class citizen, not a label:
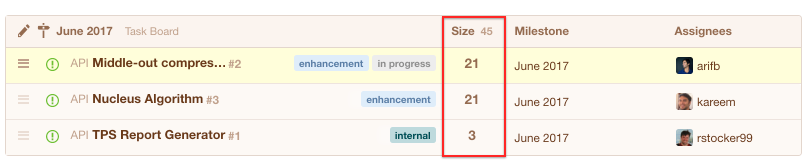
This makes it easier to quickly add or change an issue’s size:

Note when you give an issue a size in Codetree, Codetree adds it as a label to the issue in GitHub in the format of “size: n”.
For example, in Codetree an issue with a size of 5:

Would have a “size: 5” label automatically applied to it in GitHub:

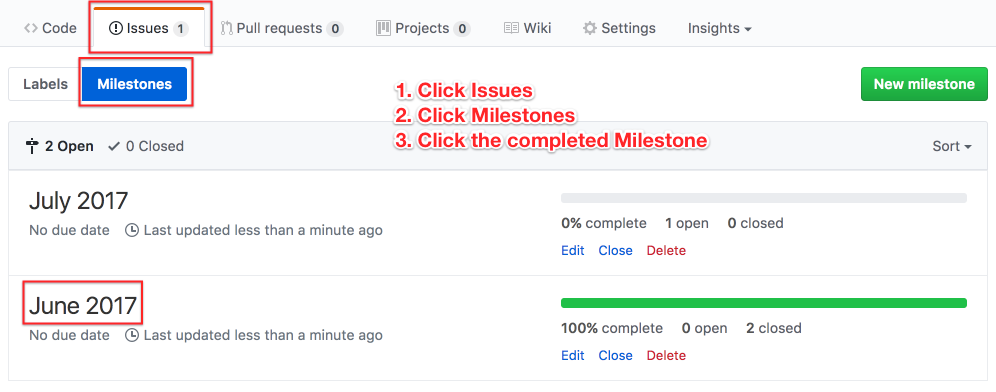
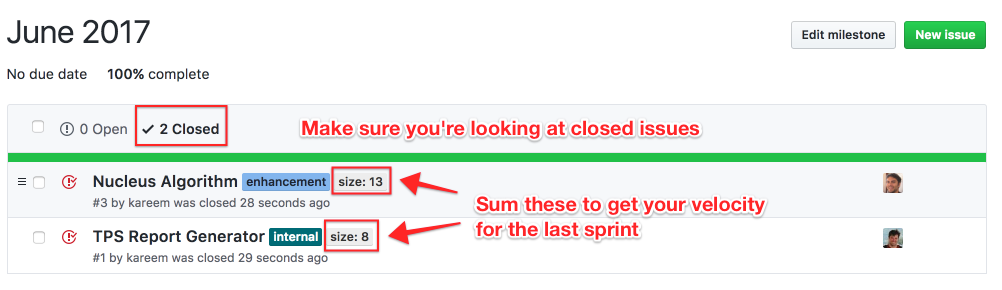
2. When a Sprint is done, sum the sizes of your closed issues
When a Sprint is done, you’d go to the list of closed issues in the Milestone:
You’d then find the list of closed issues and sum their estimates:
Since size is now a first-class citizen in Codetree, it’ll sum up your velocity completed for you:

3. Put your velocity in a spreadsheet to calculate your rolling average
You’re better off calculation velocity by averaging the past few months to smooth out spiky Sprints (sprints where you accomplished a lot more or a lot less than you usually do due to things like devs on vacation, putting out fires, etc).
GitHub doesn’t have the notion of velocity tracking so you’ll have to keep track of your velocity in a spreadsheet to find the trailing average:

2. Setting up your Backlog in GitHub
Your backlog is the queue of issues that you’ll pull from during sprint planning. At Codetree, we have a simple process to get an issue into the Backlog:
- New issues get added to Codetree with no Milestone
- We Triage unmilestoned issues regularly. During Triage, an issue will be:
- Closed, won’t fix
- Put into Backlog
- Put into current milestone (this really only happens for showstopper bugs)
We’ll also tag issues with things like “customer-request”, or “enhancement”, or “bug”, along with a priority (high / medium / low).
Once your backlog is set up and prioritized by your product owner, you need to make sure the set of issues you’re considering for the current sprint is estimated.
3. Estimating Issues in GitHub
Each team does estimation differently. Sometimes the dev lead does it, sometimes individual devs. One of the most effective ways we’ve seen is by using Planning poker. It takes advantage of each team member’s knowledge to set an accurate estimate. Estimation is outside the scope of this article. But once you’ve tagged the set of issues at the top of the Backlog with a “size: n” label, you’re ready to plan your next sprint.
4. Planning your Sprint
To plan your sprint, you’d visit your backlog, which should have been prioritized by your Product Owner. The only issues you’d consider for the sprint are the issues with a “size: n” label.
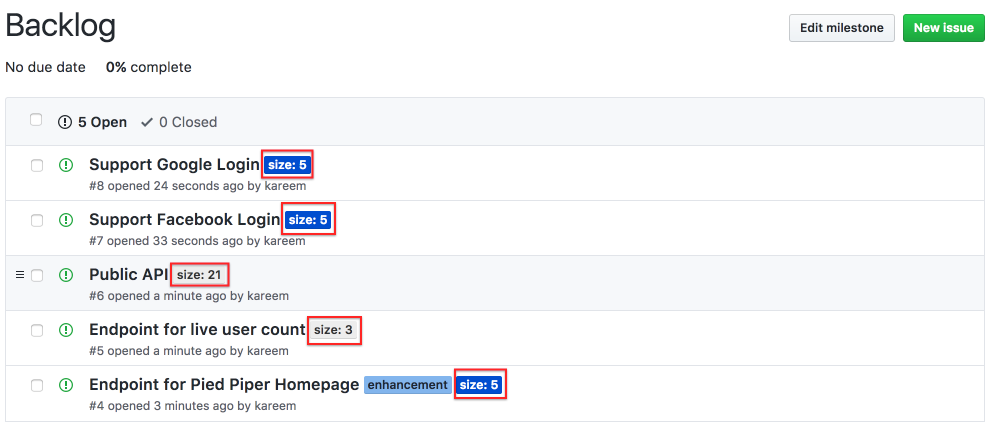
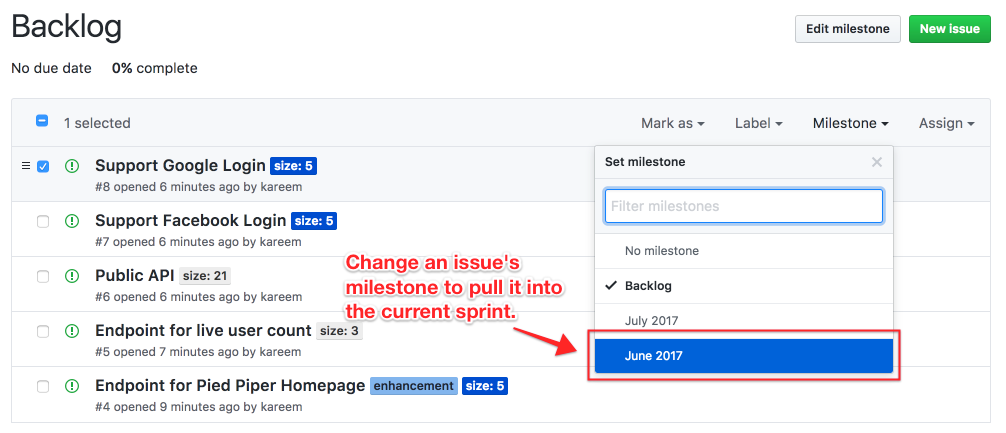
You’d pull as many issues as your velocity dictates you should into the sprint, and make sure that your Product Owner was game for the issues in the sprint (sometimes she’d want to make tradeoffs and fit two smaller features in instead of one larger one). To move an issue into your sprint, you’d just change its milestone:
In Codetree, you’d create a “Filter” to show all issues in your Backlog that have a size -- these are the issues that are eligible for the current sprint:
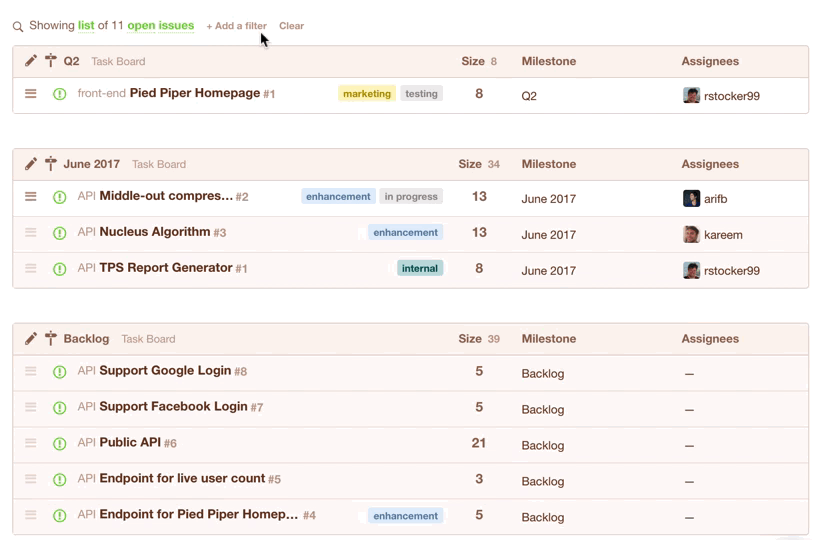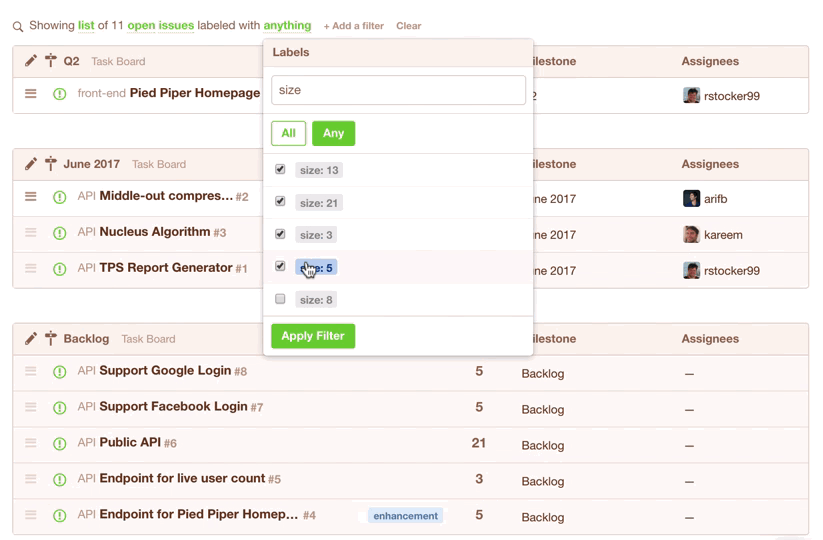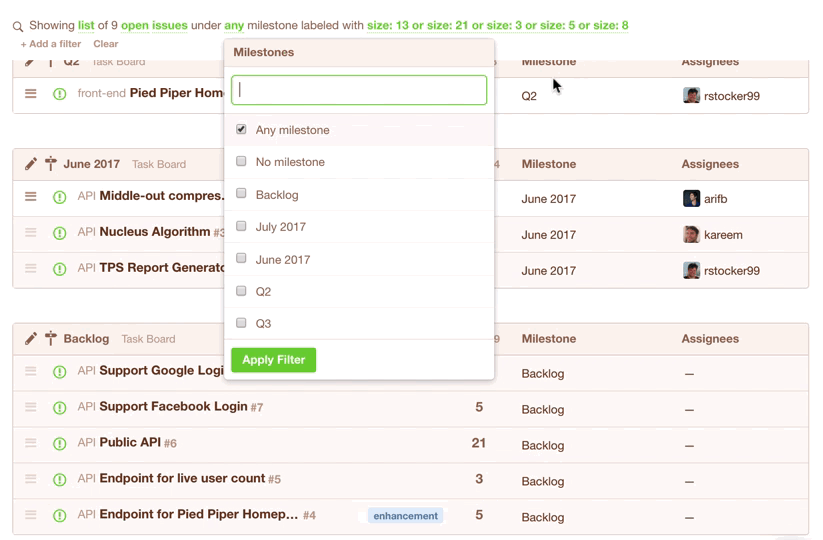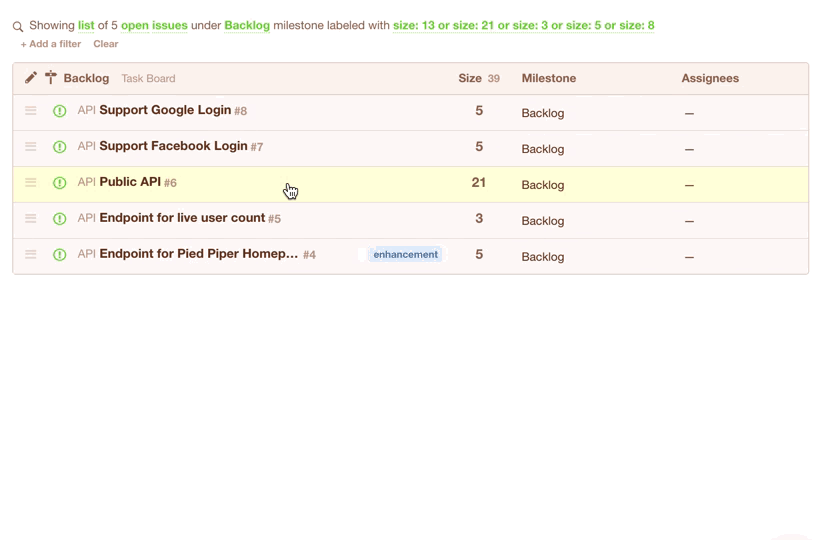
You could even save the filter for quick access during your next Sprint Planning session:
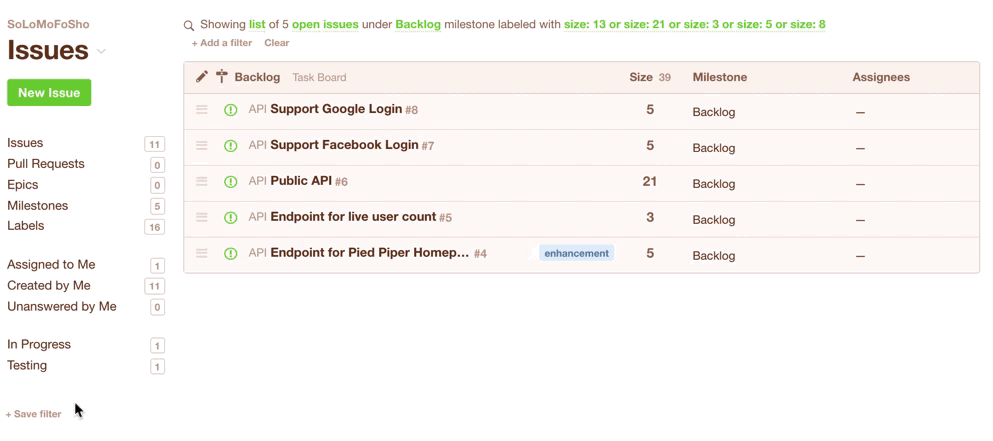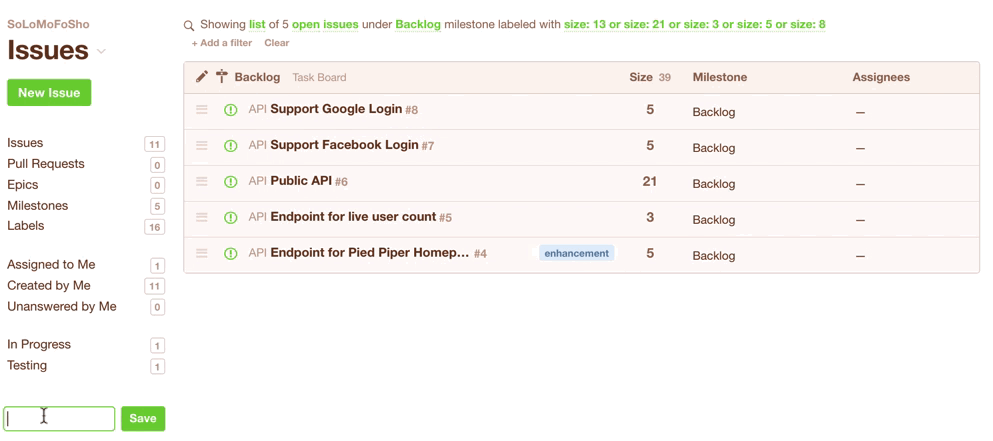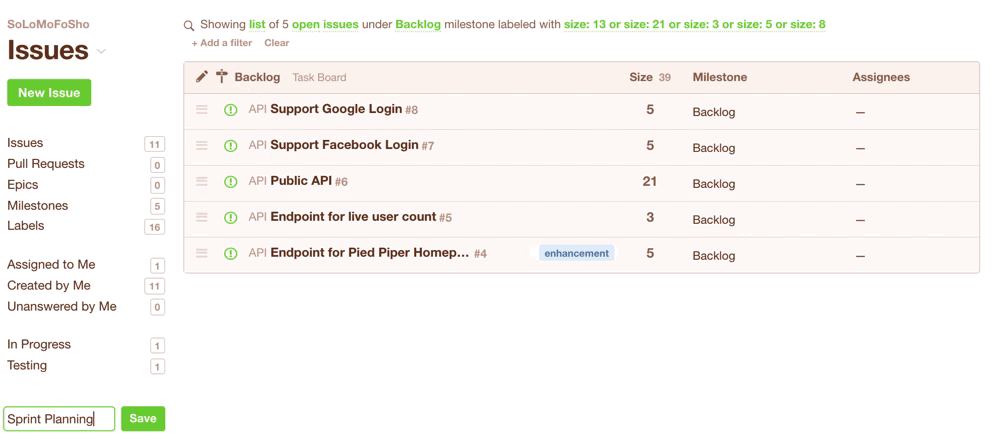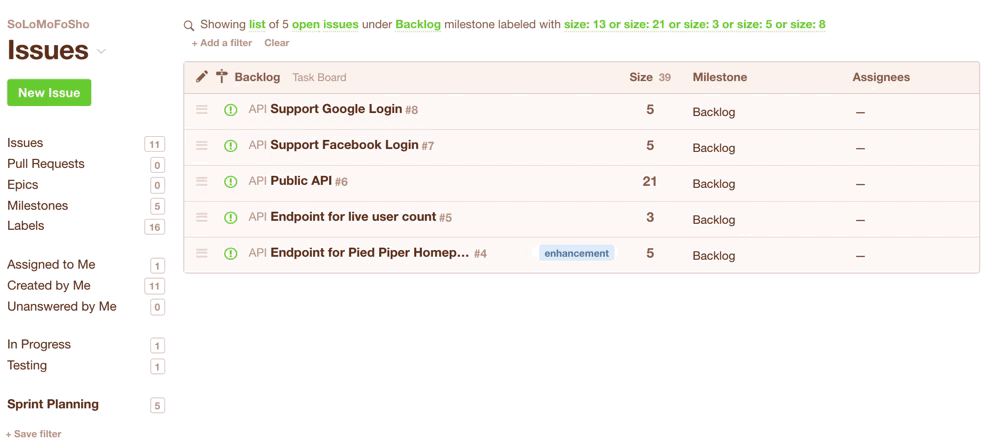
Once you’ve got your list of issues that are eligible for the current sprint, you’d simply change their milestone from “Backlog” to e.g. “July 2017”. Note they disappear from the view because you are seeing a list of issues in the “Backlog” milestone, but we’ve just moved them to the “July 2017” milestone:
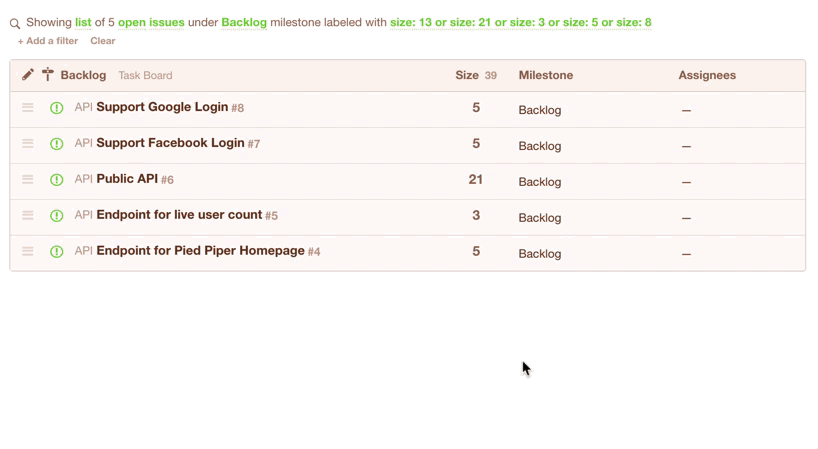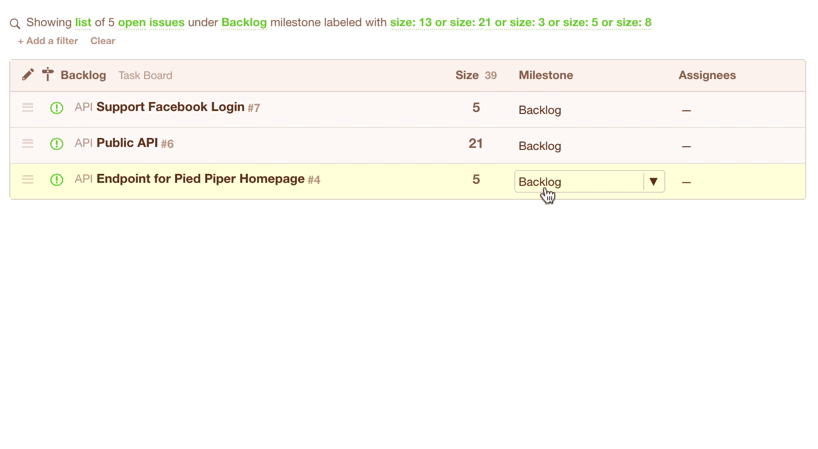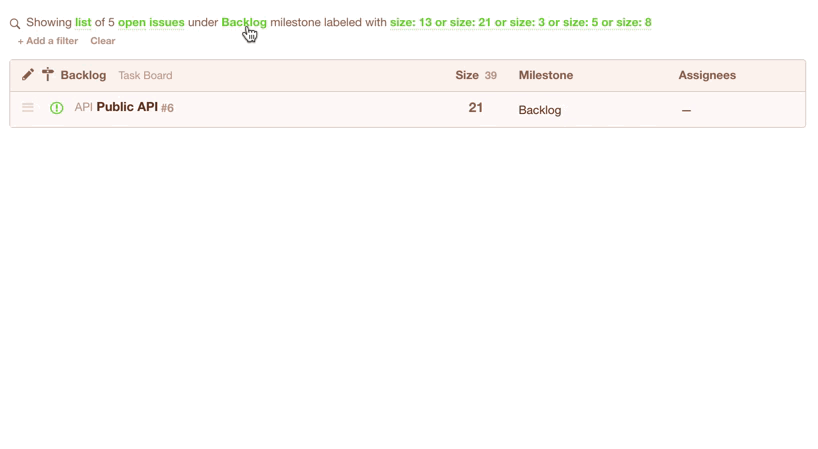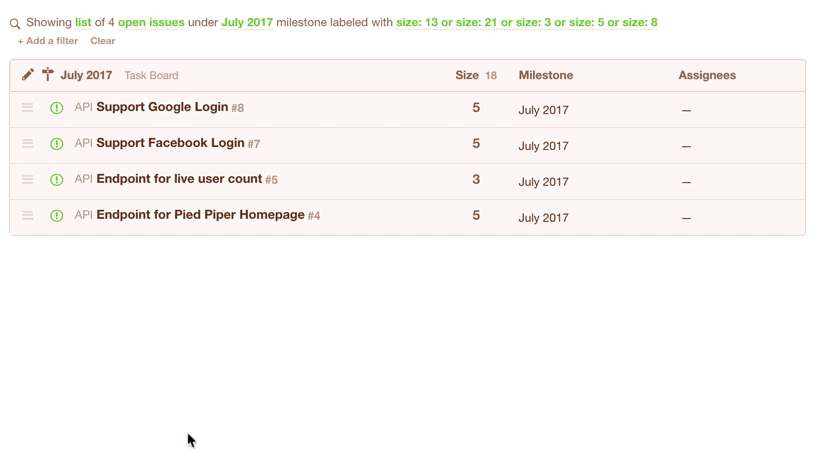
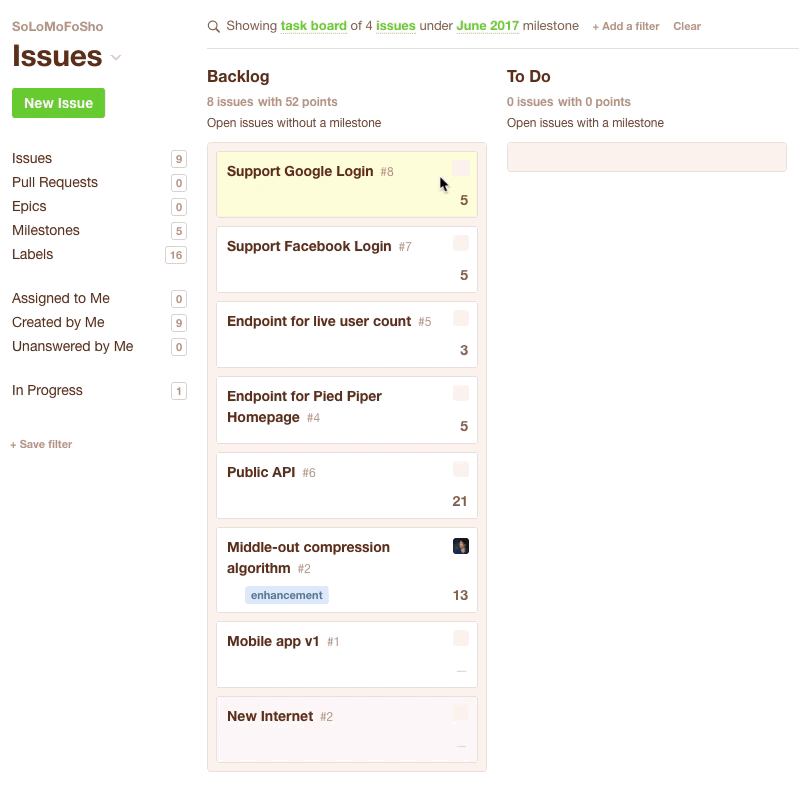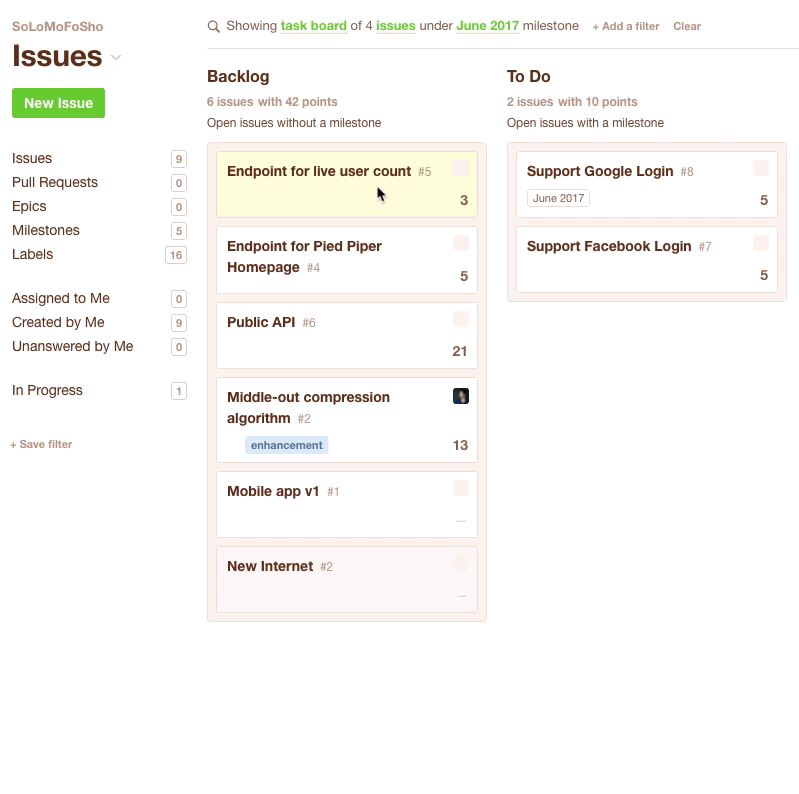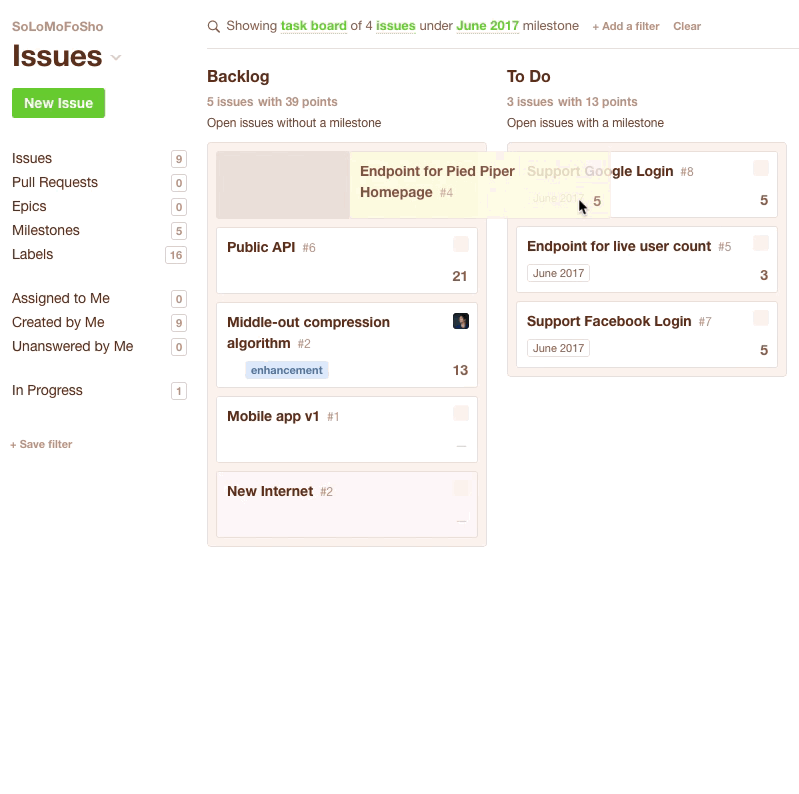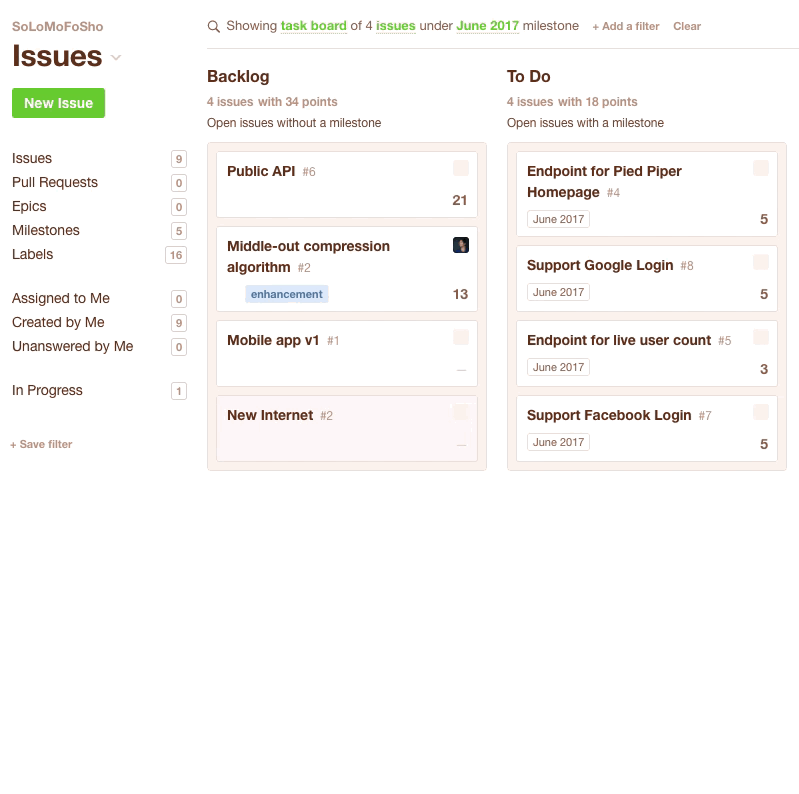
You could also do this with a Kanban Board. You just drag issues from the Backlog to the ToDo column. Be sure to keep an eye on the top of the column to see how many points you've got in the current sprint.
Once you’re done with your planning session, you’ve got your next sprint all set. It’s time to get down to the fun part - writing and shipping some code!